The Cloud is great…but it’s terribly inefficient and complex. Imagine, for argument’s sake, I wanted to deploy a simple NGINX web server on the cloud. Naively, I might look on my local disk:
felipe@local:~$ ls -lah /usr/sbin/nginx-rwxr-xr-x 1 root root 1.1M Mar 20 2023 /usr/sbin/nginxThe NGINX binary is pretty lean, weighing in at only 1.1M. How might I go about deploying such a server on the cloud? Clearly there are many ways to go about this, but one simple, relatively standard way would be to go to a cloud provider’s marketplace, such as AWS’, and use an official image, in this case based on Ubuntu:
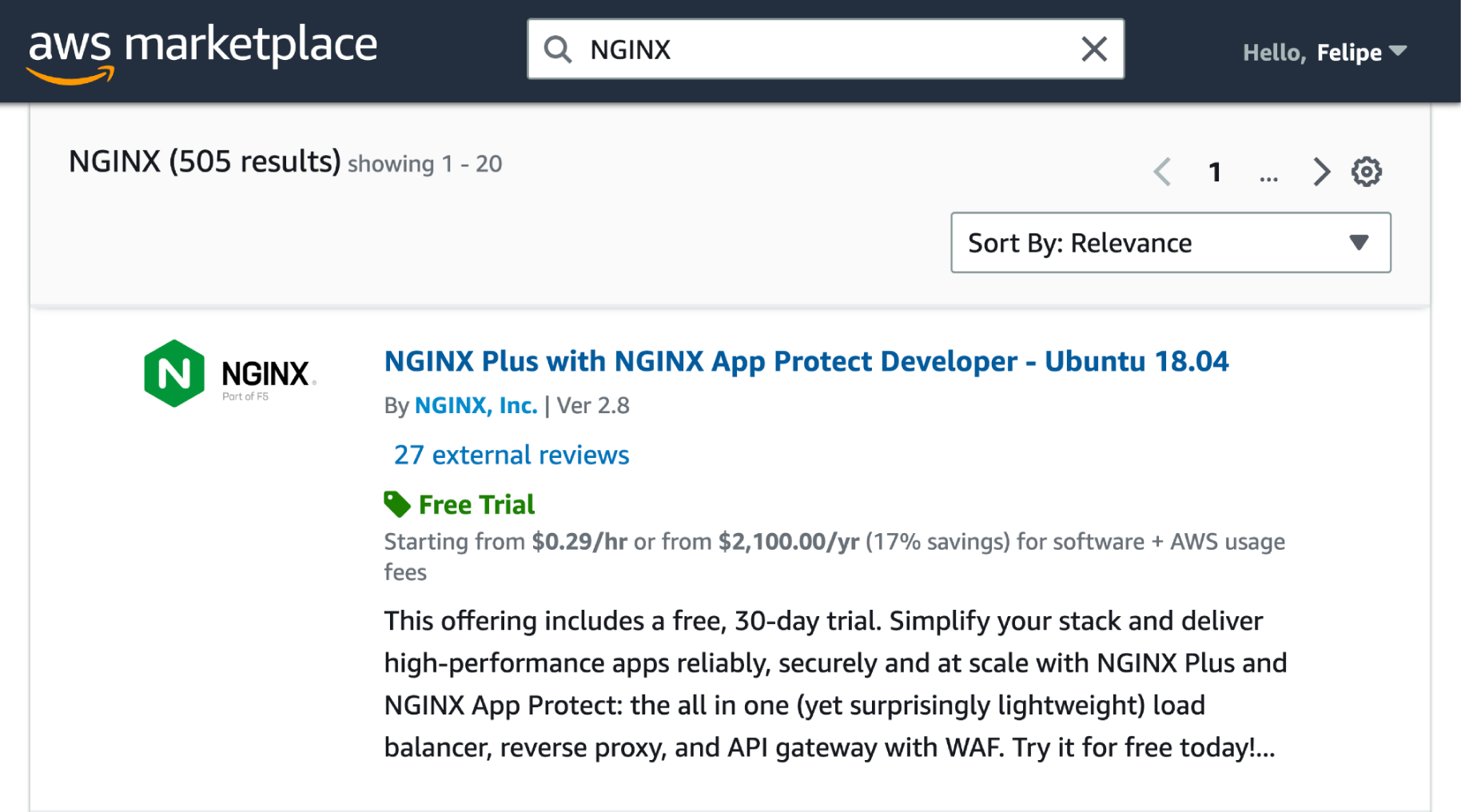
And much to our dismay, we’ll quickly realize that what was an innocent-looking 1.1MB binary has now turned into a cloud-ready, but horribly bloated, 2.6GB(!) image. Now clearly there are much leaner distros than Ubuntu, but you get the point: efficiently deploying apps to the cloud is far from easy.
The Beginning of the Problems
So say you’ve managed to deploy your app and imagine that it has no traffic going to it just yet. In this scenario, your app is idle but running, and so you’re being charged for it, to the delight of your cloud provider (but probably less yours). When traffic comes in things get better, as you’re still charged but presumably your app is now handling traffic and doing valuable work. But then traffic dies down again, the app goes idle, and you’re now getting charged again for idleness…the picture looks a bit like this:
So you get overcharged, and your cloud provider’s happy. But wait you say, I know the perfect thing for this scenario: scale-to-zero! And in a perfect world you’d be right, as scale-to-zero is intended precisely for efficiently handling intermittent traffic by stopping instances/apps when idle, and starting them, as quickly as possible, the moment new requests appear once again on the horizon. The theory looks a bit like this:
So basically off when idle, and on when requests are there, perfect right? Unfortunately, reality rears its ugly head, and scale-to-zero offerings from cloud providers (1) take seconds or minutes to initialize from a cold start when requests come in (during which you’re getting charged and you’re users are less than happy about the slow response times) and (2) take seconds or minutes to detect idleness (during which you’re getting charged). Essentially cloud traffic has millisecond dynamics, but your cloud infra provider only provides services that can react in seconds or minute timescales. A bit more like this:
So basically the periods marked “Initialization” or “Idle” are costing you money but your app isn’t doing useful work for you – and your cloud infra provider has little incentive to fix this as this inefficiency (theirs) is earning them money.
But wait! you might say: my app always has traffic coming to it, so I don’t have any of these problems. Some apps certainly fit this description, but what about handling bursty traffic and peaks?
Aha! you say: for bursty and peak traffic I have a magic wand called autoscale, which can ensure that my app horizontally scales as demand increases. But here once again reality kicks in: traffic fluctuates in scales of milliseconds, which existing autoscale mechanisms take seconds or minutes to, well, scale. To get around this, you may think of a few workarounds:
Scheduled autoscaling: assumes that, while traffic is variable, it’s regular, so you can start to scale prior to the traffic demand increasing – a big, in many cases unrealistic, assumption.
Predictive autoscaling: assumes that traffic is variable and irregular, but clever algorithms can reliably predict when peaks will happen – again, an unrealistic assumption.
Over-provisioning for peak: the mantra of many cloud deployments, essentially throw money at the problem and make your cloud infra provider happier (and richer).
At this you might even say no problem! I can deploy my app to a FaaS offering such as AWS’ Lambda, where I can get fast, millisecond autoscale. Leaving aside the large number of limitations that come with FaaS (limited support for languages, duration run times, etc, etc), you’ve now resolved how autoscale suffers the same similar problem of cold starts. On Lambda (I’ll use Lambda as shorthand to mean FaaS platforms in general), functions start quickly, in milliseconds, except when you get hit by a cold start, i.e. the function isn’t running at all and you have to start it from zero. When this is the case the start time can shoot up to hundreds of milliseconds or seconds – definitely noticeable by end users and a royal pain to deal with if you’re providing a service to them. Something like this:
As the service scaled up, it either dropped or buffered requests 1 through 3 of the spill-over traffic and it wasn’t until request 4 that the service was able to properly respond to incoming requests without any drop or delay. Here you may think you have some workarounds too:
Keep instances warm: regularly ping instances such that they’re never shut down (up to the maximum run duration limit), fixing the issue but wasting your money. Some providers even have (paid, of course) services dedicated to keeping functions warm; or,
CPU boosts, where you pay extra to have your function cold started faster by paying more money to have a CPU boost.
In all, you gotta love that cold starts are a cloud provider’s problem that gets fixed by you paying more money to the cloud provider whose problem it was in the first place – and you have to wonder how much incentive they might have to fix all of these problems… but I digress.
So to summarize, as a cloud engineer or developer:
- I can deploy an app, but I’ll pay for idle
- I can enable scale-to-zero, but I’ll still pay for idle
- I can enable autoscale to cope with bursts, but reactive autoscale is too slow
- I can use FaaS, but I have to deal with cold starts
- I could use a mixture of products for different services, causing me headaches
- I could start with FaaS when small, but will need to switch when my app grows
At this point it might be worth pointing out that these are cloud infra issues that in all honesty should be handled by cloud infra providers, not the poor souls running services on them.
What’s the Root Cause Behind this Mess?
Clearly these issues are not by design, but the (unfortunate) emergent properties of the underlying technology being used to run our cloud infra. If we were to go back to first principles, and we could design a lean, efficient, purpose-built cloud stack, what would it look like? Well, probably something like this:
Simply, the hypervisor is the golden standard for providing strong, hardware-level isolation in multi-tenant environments, so that’s a must. Above it must come a virtual machine, and ideal one with very little else than the app – since the app is arguably the only thing we really care about when deploying to the cloud; anything else is overhead as far as we’re concerned.
The reality though looks far from this ideal, and a lot more like this:
From the bottom up, it all starts well enough, with the ideal hypervisor + virtual machine model – but that’s where things start to go awry. I’ll point my first finger at the OS: unfortunately, on the cloud, we almost exclusively rely on general-purpose OSes that contain a lot more functionality (and vulnerabilities) than the application actually needs to run. OSes such as Linux are certainly extremely useful, but far from cloud-native and in fact pre-date the cloud.
Next up is the user/kernel space divide typical of such OSes: Linux, Windows, and the like, were to run on bare metal and provide multi-user environments, and so such divide definitely makes sense. In a cloud deployment, where the OS is sitting on top of a hypervisor which already provides strong isolation, the user/kernel space divide doesn’t provide much, and certainly results in (unnecessary) overhead.
Enter now the container runtime, for, well, yet-one-more-layer-of-unneeded isolation. Don’t get me wrong, containers are incredible for dev and build environments, and for that purpose I cannot speak highly enough of them. When you go to deploy them in the cloud however, where there’ll be anyways running inside a strongly isolated VM, they start to make a lot less sense. And not to belabor the point, but you then have a ton of libs and services your app may not need, language-level run-times – and at the top of that mountain, your app… something like this:

And the above refers only to the cloud stack. Add to this controllers that take seconds or minutes to take action, slow load balancers and heavy-weight virtual machine monitors such as QEMU and it starts to become clear why we’re chronically over-paying and over-provisioning when deploying our services on the cloud.
This concludes the first part of this post; in part 2, we’ll go back to first principles to see how the cloud could (and arguably should) be run, and how none of the current problems with cloud infra are fundamental.
Get early access to the Unikraft Cloud
Unikraft Cloud has free early access, so if you find it intriguing and would like to get a taste of what a next generation compute cloud platform looks like:



