As an ice breaker, I sometimes open talks at conferences with the following question:
When I present this, I first only show the question, and have the audience yell out guesses. Surprisingly, but also logically enough, the highest number I ever got was about 100 VMs on a server. I say logically because when you take into account how heavyweight typical VMs can be (yes, I know, with distros like Alpine you can put this down, but for most cases we’re talking in the GBs range), and the fact that in many deployments they run forever, even if idle, we start to see why a “measly” 64-core server might not be able to cope with that many VMs.
Are VMs a Must? And Must they be Heavy?
On public clouds, the hypervisor/VM model is the golden standard for providing the strong, hardware-level isolation needed for multi-tenancy, so a bit of a must, yes. In fact, in the public cloud, almost all deployments* are done on top of a VM, whether you know it or not; even deploying a container on the cloud means that it’ll be running with a VM underneath.
Normally asterisks get relegated to the footer or end of document, but I couldn’t resist promoting it to here: there are in some cases deployments based on language-level isolation mechanisms, such as isolates in the case of v8, but these provide weaker security guarantees than a hypervisor/VM – apologies in advance for the digression.
So now to the second question: are virtual machines fundamentally heavy? Well, it depends what you put in it, so fundamentally no.
When deploying to the cloud, in most cases we have a huge advantage: we know exactly what application or service we want to deploy before we actually deploy it. This means that we could, in principle, build a custom operating system and distro for our app, if only we had a magic wand that could do this for us simply and in an automated way. What we’d have then would be a highly specialized VM containing only the code that our app needs to run, plus our app, and nothing more. In essence, we’d like to revert the following:
The technical term for such a specialized VM is a unikernel. Unikernels are typically based on a library operating system, that is, a modular OS, in order to maximize the level of specialization of the resulting VM images. In our case, we created the Unikraft Linux Foundation project many years ago as a unikernel development kit to make it easy to build such unikernels. In addition to efficiency, one of the key tenets of Unikraft was to ensure POSIX compatibility so that unmodified Linux applications could run on it (something akin to Linus’ “don’t break userspace”). Unikraft supports something called binary compatibility mode, allowing users to provide a standard Linux ELF that then gets (transparently) built into a unikernel.
Ok, so enough chatter, what happens if we were to use unikernels? By way of example, if we take an NGINX server (ELF) and build a Unikraft unikernel for it, we end up with an image of about 1.6MB on disk (the NGINX binary is roughly 1.1MB):
kraft cloud image ls --allNAME VERSION SIZEnginx latest 1.6 MB[...]When deployed, the image only needs 16MBs to actually run:
[●] Deployed successfully! │ ├────────── name: nginx-6cfc4 ├────────── uuid: 62d1d6e9-0d45-4ced-ad2a-619718ba0344 ├───────── state: running ├─────────── url: https://long-violet-92ka3gk7.fra0.kraft.host ├───────── image: nginx@sha256:fb3e5fb1609ab4fd40d38ae12605d56fc0dc48aaa0ad4890ed7ba0b637af69f6 ├───── boot time: 16.65 ms ├──────── memory: 16 MiB ├─ service group: long-violet-92ka3gk7 ├── private fqdn: nginx-6cfc4.internal ├──── private ip: 172.16.6.4 └────────── args: /usr/bin/nginx -c /etc/nginx/nginx.confTowards High Server Density
So we’re no longer in the realm of the GB-sized VM, but what can we do with such a unikernel beyond these basic stats? The first thing s to just take it out for a (stress test) spin:
Here we first create a single NGINX unikernel and measure its cold start time (about 6 milliseconds). We then leave it running, create a second one and measure its start time, all the way to 5,000 virtual machines. The start time goes up slightly since even an idle unikernel will consume some resources (though the start time still sits at a relatively low 14 milliseconds for the 5000th VM).
Next, let’s try to push the system to its limits. To do this we had to do a number of tweaks to the underlying Linux host (we’re using KVM as the hypervisor), mostly to do with limitations in Linux’s networking system.With those out of the way:
So about 90,000 virtual machines on a single server (which incidentally, has 64 cores and 1TB of memory); after that we start to run out of physical memory. 🙂
Clearly this is only meant as a stress test: the actual instances are idle, and so in a realistic scenario with actual traffic the system would keel over. Still, it’s always good to know where the limits of a system actually are, and this certainly goes beyond the 100 number that I heard shouted/guessed at me at conferences.
The Millisecond Scale to Zero Multiplier
Stress tests are nice, but realistic deployments are even nicer. Imagine I’m a company providing a cloud-based service and I have a largish user base, say 1 million users. In most cases, not all of these users will be active at the same time, so there’ll be a long tail of inactive users. How much capacity (how many servers) would I need to serve my entire user base? With standard tech, since I don’t know which users will become active when, I’d have to plan for peak capacity, over-provision, and seriously overspend.
In fact, most cloud traffic is intermittent and bursty in scales of milliseconds. Given this, the ideal case would be to be able to bring up services up in milliseconds, just-in-time, as requests arrive (and then shut down immediately, also in milliseconds, so as to not waste resources). Such millisecond scale to zero would allow for servers to be provisioned not for peak traffic, but for how many active users are likely to hit a server. For instance, from the 1M user base above, assuming:
- Only 1,000 users, at most, are concurrently active; and,
- One server (in terms of CPU, memory and disk resources) can handle 100 users.
Millisecond scale to zero would allow me to handle my 1M user base with just 10 servers. Here’s a picture to illustrate:
Basically with a standard server deployment (left), you’d have largish instances, many of them idling (because starting them up would take too long, and in order not to degrade user experience it’s just better to leave them idling, ie, overprovisioning).
With Unikraft Cloud (right) instances are not only lightweight, so lots more can fit onto a single server, but thanks to millisecond scale to zero, many or most of them can be on “standby”, meaning that:
- They don’t consume any CPU or memory resources; and,
- They can still respond to requests in milliseconds.
In simple words, order-of-magnitude higher efficiency. To make it more concrete, here’s a screenshot of one such Unikraft Cloud server running over 10,000 NextJS instances without breaking a sweat:
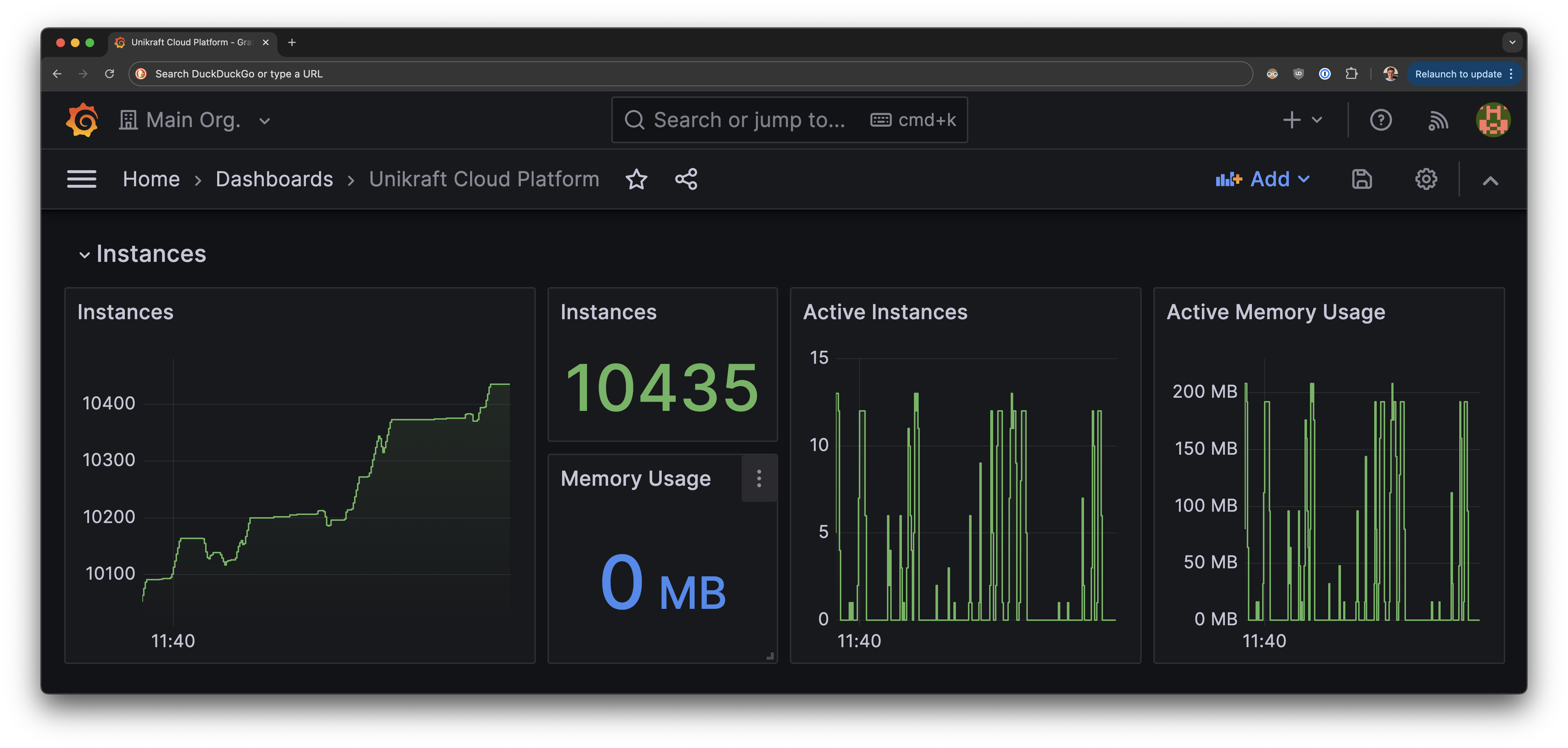
The 10K+ instances are all on standby (scaled to zero) so consume no CPU nor memory resources (thus Grafana showing 0MB), as far as users are concerned, things are always up and running, but on the server side the story is actually quite different.
How to Get Started
You can drop me a line on LinkedIn or at find a time talk directly, but basically:
- Rent a bare metal server from any provider (e.g., an AWS “metal” instance, or servers from the likes of Equinix, Vultr, Hetzner, etc.);
- Select a basic Linux host install (we prefer Debian, but other distros will do);
- We install Unikraft Cloud software on it;
- We take care of integrating with your CI/CD system or whatever other app/service deployment system you may have in place.
Beyond this, if you’d like to give it a try first, you can sign up for free to our hosted platform today.

